
Budget de Crawl : Guide complet pour son optimisation SEO
Budget de Crawl (ou Crawl Budget ) est un terme créé par la communauté SEO qui se réfère à la fréquence à laquelle les moteurs de recherche peuvent et veulent crawler votre site Web.
Il s'agit d'un concept SEO technique important surtout quand vous travailler sur des gros sites Web à fort volumétrie de trafics par exemple certain site e-commerce.
Dans ce guide Budget de Crawl je vais couvrir ce qu'est un budget de crawl, pourquoi il est important, et comment l'optimiser pour améliorer les performances SEO de votre site.
C'est quoi le budget de crawl ?
Le budget de crawl est le nombre d'URLs que Googlebot va parcourir sur votre site en moyenne chaque jour. Deux facteurs déterminent votre budget crawl :
- Le nombre de requêtes que votre site peut traiter avant de répondre avec des erreurs de serveur.
- La popularité de votre site web sur Internet. Et à quel point l'URL est devenue obsolète dans l'index de Google.
Voilà comment Google définit le budget de crawl :

Limite de vitesse du crawl budget
La limite de vitesse de recherche est conçue pour aider Googlebot à ne pas parcourir vos pages trop souvent et trop vite pour ne faire sauter votre serveur.
L'objectif de Google n'est pas de dégrader l'expérience d'utilisateur des personnes qui visitent votre site Web. Par exemple, si Googlebot demande trop de pages à la fois, Googlebot (et les utilisateurs) obtiendra 5xx codes de réponse HTTP :
Ainsi, Google ajustera la limite de vitesse de recherche vers le haut ou vers le bas en fonction de la façon dont votre serveur répond à leur activité.
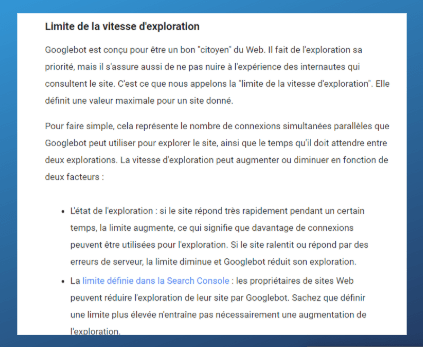
Vous pouvez lire ce que Google dit au sujet de la limite de la vitesse d'exploration ci-dessous :
Demande de Crawl
La demande d'exploration c'est le cas ou Googlebot veut parcourir vos pages. La “demande” est basée sur la popularité de vos pages par exemple les backlinks et sur l'ancienneté du contenu dans l'index Google.
Google aura tendance à parcourir les pages qui ont beaucoup de backlinks plus fréquemment que celles qui n'en ont pas beaucoup. De plus, si votre contenu change régulièrement, Googlebot visitera ces pages plus souvent qu'un site statique.
Vous pouvez lire ce que Google dit sur la demande de crawl ci-dessous :

Pourquoi optimiser son budget de crawl ?
Le crawle est une partie fondamentale du SEO , et sans les moteurs de recherche il n'y a pas de crawl pour votre site Web, vous ne serez jamais en mesure de classer dans le SERP de Google.
Ainsi, la compréhension, le contrôle et l'optimisation de votre budget crawl est une partie cruciale de votre succès SEO. On va voir les trois raisons pour lesquelles je crois que l'optimisation du budget crawl est vitale pour le référencement naturel.
Votre contenu ne peut pas être indexé et hiérarchisé sans être crawlé.
C'est aussi simple que cela. Votre contenu n'apparaîtrait pas dans Google si Googlebot ne l'a pas parcouru. L'utilisation efficace de votre budget de crawl est important pour que les moteurs de recherche puissent parcourir vos pages stratégiques et les classer ensuite dans le SERP.
Orienter votre crawl vers vos pages stratégiques
Vous voulez que Googlebot passe la plupart de son temps à parcourir des pages qui vous rapportent de l'argent, non? C'est ça l'optimisation du budget de crawl, pousser Googlebot vers vos pages pour des conversions. Un autre point Google ne crawl jamais toute la totalité d'un site d'un coup. Alors, pas de panique.
Faire découvrir et mettre à jour rapidement votre contenu
Le contenu de tous les sites Web n'est pas statique. Certains sites mettent à jour leur contenu de façon dynamique plusieurs fois par jour. Et d'autres ajoutent de nouvelles pages chaque jour.
Si c'est le cas, vous voulez que Googlebot parcoure ces pages fréquemment pour vous en assurer :
- Les nouvelles pages se classent et génèrent du trafic organique.
- Le contenu mis à jour est frais dans l'index de Google.
Si Google perd du temps à parcourir des pages de faible valeur, c'est que vous n'utilisez pas efficacement votre budget de crawl. Et là vous avez un souci.
En fin de compte, l'optimisation du budget crawl est importante pour le référencement, car elle permet à Googlebot d'accéder rapidement aux pages qui vous rapportent le plus et fréquemment. C'est pour cela il faut faire un petit nettoyage au niveau des URLs quand c'est nécessaire avec méthode.
Qu'est-ce qui affecte le budget crawl ?
Vous vous posez peut-être la question : “Qu'est-ce qui peut avoir un impact négatif sur le budget crawl ?
Disons toute URL qui ne rapporte pas de l'argent à votre entreprise ou qui n'offre aucune valeur aux utilisateurs (ou à Google). Alors, pourquoi on parle de gaspillage de budget de crawl et comment les réparer dans la section suivante. Bon je vais essayer… 🙂
Mais pour vous donner un bref aperçu, voici ce que dit Google :

Comment optimiser votre budget crawl
La meilleure façon de maximiser votre budget d'exploration est de passer en revue les fichiers journaux ( ou Analyser vos logs ) de votre serveur pour comprendre ce que Googlebot est en train de crawler.
N'oubliez pas de lire mon Guide sur l'Analyse des fichiers de logs: un guide de référencement.
Voici mes meilleurs conseils pour optimiser votre budget crawl :
- Avoir une structure de site bien planifiée
- Améliorez la vitesse de chargement des pages de votre serveur.
- Utilisez les liens internes pour les pages importantes.
- Nettoyer les chaînes de redirection
- Ne laissez pas Google explorer les paramètres d'URL inutilisés.
- Limite des réponses non-200
- Fournir des pages importantes dans les sitemaps XML
- Utilisez un fichier robots.txt pour contrôler Googlebot
- Visez une URL par élément de contenu.
- Ne donnez pas de signaux contradictoires à Googlebot.
- Évitez les chiffres élevés sur les pages non indexées et crawlables.
- Ne permettez pas d'espaces infinis.
Maintenant comment vous pouvez l'utiliser pour optimiser votre budget crawl.
Avoir une structure de site bien planifiée
La structure du site est vitale pour fournir des chemins de recherche clairs pour Googlebot. Une structure de site plate est parfaite pour distribuer le PageRank à vos pages. C'est ça qui est le plus important. Une structure de site plate est généralement définie en ayant des pages d'importance pas plus de trois clics de la page d'accueil.
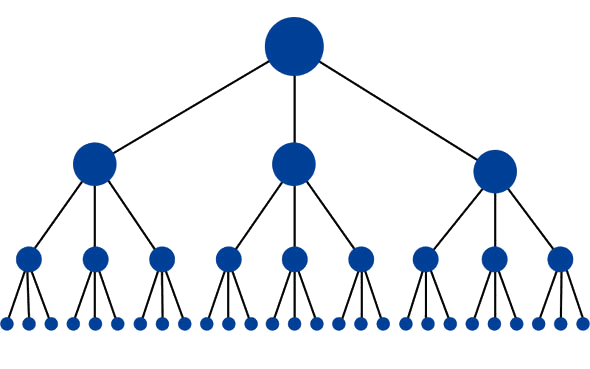
Googlebot parcourra les pages qui ont un PageRank plus élevé plus fréquemment que celles qui ne sont pas en haut dans la structure du site.
Améliorez la vitesse de chargement des pages de votre serveur.
Google détermine la limite de vitesse de recherche en fonction de la façon dont votre serveur répond aux requêtes de Googlebot. Si vous augmentez la capacité de vos serveurs à réagir rapidement à Googlebot, vous pouvez augmenter le nombre de visites que vous recevez par jour. Un CDN pourra faire la différence.
Utilisez les liens internes pour les pages importantes.
Les liens internes sont ce que Googlebot va suivre sur votre site au fur et à mesure de son exploration. Il est essentiel que vous planifiez votre stratégie de liens internes, afin que les pages qui vous tiennent le plus à cœur aient le plus grand nombre de liens.
Vous devriez éviter de créer des liens vers les pages suivantes :
- URLs qui ne renvoient pas un code de statut 200.
- URL qui est canonisée à une autre URL.
- Des URL qui ne vous rapportent pas d'argent.
Les liens vers ces URLs gaspillent votre budget de crawl sur des pages qui ne vous rapportent pas d'argent.
Nettoyer les chaînes de redirection
Les chaînes de redirections il faut les stopper dans cas car elles vont bouffer votre budget de crawl très rapidement. Une chaîne de redirection est lorsqu'une URL redirige vers une autre URL, puis cette URL redirige vers une autre et ainsi de suite. Googlebot suivra jusqu'à 5 sauts de redirection, donc chaque sauts que vous avez est un gaspillage de budget de crawl. Comme vous pouvez le voir sur cette image d'oncrawl.

Vous devez éliminer toute chaîne de redirection sur votre site Web et vous assurer que toutes les redirections sont un à un. Vous pouvez trouver des chaînes de redirection à l'aide de logiciel de crawlabilité tel que Screaming Frog.
Ne laissez pas Google explorer les paramètres d'URL inutilisés.
Les paramètres URL sont préjudiciables à votre budget d'exploration s'ils ne sont pas gérés efficacement. Dans un monde idéal, Google ne devrait jamais explorer les paramètres. Ils sont destinés à l'interaction de l'utilisateur, comme le tri et la commande, et Googlebot n'a pas besoin de les voir.
Si vous utilisez des paramètres pour classer les URLs, vous devez les convertir en URLs SEO. Vous pouvez gérer l'exploration des paramètres dans Google Search Console.
Cependant, je vous recommande d'être plus agressif. Si l'URL d'un paramètre ne génère pas de trafic organique, alors :
- Ajoutez une balise noindex à toutes les URLs contenant le paramètre
- Attendez qu'ils disparaissent de l'index de Google.
- Empêchez-les d'être crawlés dans le fichier robots.txt
Limite des réponses non-200
Chaque URL que Googlebot demande compte pour votre budget de crawl, donc vous voulez que chaque appel en vaille la peine. Toute réponse qui n'est pas un 200 OK est un gaspillage essentiel de crawl. Pour cela il faut faire du monitoring de logs pour comprendre où Googlebot reçoit les réponses 3xx, 4xx et 5xx et essayer de les nettoyer. En fait Google n'a pas une énergie infinie à consacrer à l'exploration de votre site, c'est pour cela qu'on parle souvent de quota de crawl.
Fournir des pages importantes dans les sitemaps XML
Google trouve des liens à partir des balises. href et des sitemaps XML, il est donc crucial de fournir à Googlebot une liste de vos liens les plus importants sous la forme de Sitemaps XML. Le XML sitemaps doit inclure :
- URLs qui vous font gagner de l'argent
- URL qui répondent avec 200 OK
- URLs avec ne contiennent pas de balise meta no-index
- Les URLs ne se canonisent pas à une URL différente
Utilisez un fichier robots.txt pour contrôler Googlebot
Le fichier robots.txt est votre meilleur ami pour l'optimisation de votre budget crawl. Utilisez le fichier robots.txt pour empêcher Googlebot de parcourir des pages intutiles.
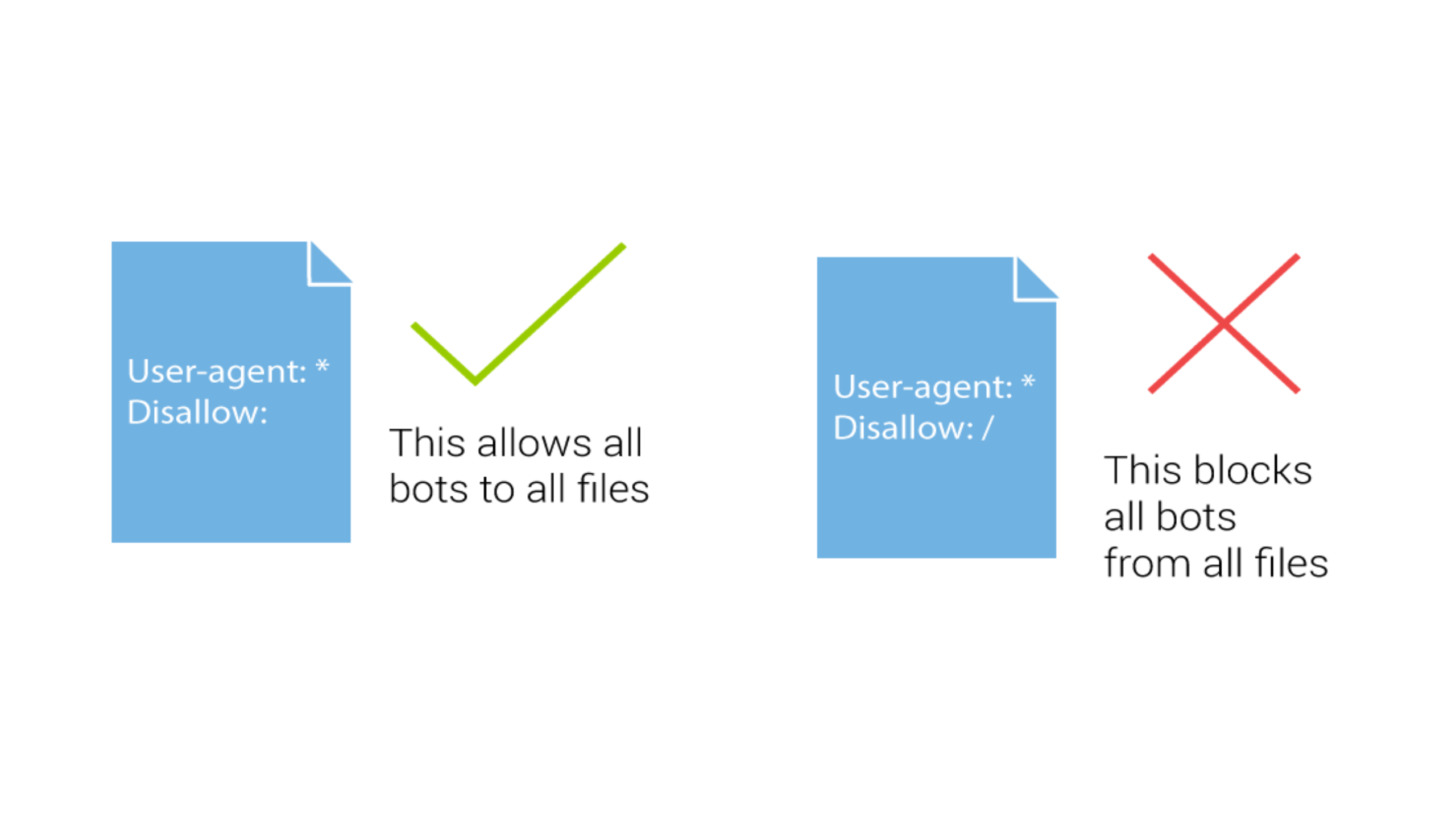
Voici quelques exemples de pages que vous devez bloquer dans robots.txt :
- Pages de connexion
- Pages des membres
- Panier d'achat
- Résultats de la recherche
- Paramètres à facettes multiples
Visez une URL par élément de contenu.
Dans un monde parfait, vous avez une URL qui représente chaque élément de contenu que Googlebot va parcourir. Si vous y parvenez, vos efforts d'optimisation de votre budget crawl seront un succès.
Il y a une optimisation simple qui peut vous empêcher de montrer plusieurs versions de la même URL à Googlebot. En voici quelques-unes :
- Est-ce que votre site web retourne 200 OK pour la version www et non-www ?
- Est-ce que votre site web retourne 200 OK pour la version HTTP et HTTPs ?
- Est-ce que votre site Web retourne 200 OK pour la barre oblique arrière et la barre oblique non arrière ?
Choisissez une version préférée de votre nom de domaine et assurez-vous que tout le reste y est redirigé directement.
Ne donnez pas de signaux contradictoires à Googlebot
Un autre perte pour votre crawl budget est l'utilisation abusive d'éléments de balises HTML envoyant des signaux contradictoires à Googlebot. Voici quelques exemples à surveiller :
- Liens internes vers des pages qui canonisent vers une autre page
- Liens internes vers des pages marquées noindex
- Liens internes vers des URL qui redirigent vers une autre URL
Chacun de ces scénarios dit à Googlebot : “Hé, tu devrais parcourir cette page. Oh, attends, non, tu devrais crawl moins souvent cette page“. Vous risquez d'avoir de sérieux problèmes.
Il est essentiel que vous utilisiez chaque signal sur votre site Web pour envoyer des messages clairs à Googlebot sur ce qu'il faut crawler et ce qu'il ne faut pas crawler.
Évitez les chiffres élevés sur les pages non indexées et crawlables.
Souvent on entend cette idée fausse que les pages marquées noindex ne sont pas parcourues. Ce n'est pas vrai. Googlebot visitera toujours les pages qui sont marquées noindex.
Il est essentiel que vous évaluiez que vous utilisez la bonne action lorsque vous n'avez pas de pages indexer. Posez-vous la question :
- Est-ce que j'ai des utilisateurs pour accéder à cette page ?
- Est-ce que je veux que cette page soit classée sur Google ?
Si vous avez répondu oui à la question 1 et non à la question 2, alors :
- Supprimer les références dans les sitemaps pour cette URL
- Essayez de limiter le nombre de liens internes à l'URL
- Ajouter une balise noindex à l'URL
Si vous avez répondu non aux deux questions, vous devez supprimer l'URL :
- Servez-vous d' un 410 pour toute demande d'URL ( suppression définitive de cette page)
- Attendez qu'il disparaisse de l'index de Google
- Empêchez-les d'être crawl dans le fichier robots.txt
Tu vois où je veux en venir ? Toutes les URL que vous affichez à Google via des liens et dans le sitemap seront parcourues. Donc, s'il ne vous apporte aucune valeur, alors débarrassez-vous en !
Ne permettez pas de scroll infini.
Les scroll infini sont un cauchemar pour votre budget crawl. Les espaces infinis se réfèrent au moment où Googlebot peut continuer à suivre les URLs dans une boucle infinie qui ne finira jamais.
Les exemples classiques de scroll infini sont les URLs de génération automatique de dates codées en dur. Imaginez que vous avez un lien vers “le mois prochain“, et que chaque page a un nouveau lien vers le mois suivant. Ce processus peut durer éternellement !
Un autre exemple est la pagination si chaque nouvelle page est liée à la page suivante de la série et renvoie un code de réponse de 200, même si la page n'existe pas.
Comme vous pouvez le voir, les “scroll infini” peuvent vous faire perdre beaucoup et très rapidement votre budget de crawl. Méfiez-vous de cela et assurez-vous d'arrêter Googlebot dans sa course folle avant qu'il ne s'engage sur un chemin de scroll infini.
Foire aux questions à propos de Crawl Budget
Le budget crawl est souvent un sujet mal compris et de nombreuses questions courantes sont posées. Voici donc mes réponses aux questions qui me sont fréquemment posées.
Quand devrais-je m'inquiéter du budget crawl ?
Le budget de crawl peut devenir un problème si vous gérez un site Web de grande ou moyenne taille avec un taux de mise à jour fréquent (de une fois par jour à une fois par semaine). Dans ce cas, un manque de budget de crawl pourrait créer un retard d'indexation permanent.
Ce problème peut également se poser lors du lancement d'un nouveau site Web ou de la refonte d'un ancien site, lorsque de nombreux changements se produisent rapidement. Bien que ce type de retard d'indexation finisse par se résorber de lui-même.
Quelle que soit la taille du site Web, il est préférable d'effectuer au moins une fois un audit pour détecter d'éventuels problèmes de crawling. Si vous gérez un grand site Web, faites-le maintenant, si vous gérez un petit site Web, mettez-le simplement sur votre liste de choses à faire.
Le budget crawl n'est pas quelque chose à laquelle la plupart des sites Web ont besoin d'y penser. Vous devriez commencer à tenir compte de votre budget de crawl dans les scénarios suivants :
- Si les nouvelles pages ne sont pas parcourues le jour même où vous les mettez en ligne.
- Si votre site Web a plus de milliers d'URLs.
- La découverte rapide de votre contenu par Googlebot est cruciale (par exemple, les sites web d'actualités).
- Vous générez automatiquement un grand nombre de paramètres URLs.
Cependant, je recommande que chaque site web prenne en compte la fenêtre de crawl de ce que Googlebot crawl et à quelle fréquence au moins une fois. Ce n'est pas quelque chose que vous aurez besoin de surveiller continuellement, mais vous devriez avoir une idée. Comme l'a dit l'autre : “Tu es ce que Googlebot mange”. Possibilité d'un monotoring de log.
Comment puis-je vérifier mon budget de crawl ?
Vous pouvez vérifier votre budget crawl de deux façons. La façon la plus simple est de vérifier le rapport des statistiques de recherche dans Google Search Console. Cependant, je recommande d'effectuer une analyse log.
La deuxième option consiste à consulter les fichiers de log d'accès de votre site Web pour savoir qu'elles sont les pages que Googlebot visite. L'analyse des fichiers log est un outil très puissant et vital pour comprendre votre budget de crawl.
Comment augmenter mon budget crawl ?
Pour augmenter votre budget crawl, vous devez tirer sur l'un des deux leviers qui le définissent : limite de vitesse d'exploration ou demande d'exploration. Malheureusement, il n'y a pas de bouton rouge sur lequel vous pouvez appuyer pour augmenter instantanément votre budget crawl.
Pour augmenter votre limite de vitesse d'exploration, vous devez améliorer la vitesse à laquelle votre serveur répond aux requêtes. Pour augmenter votre demande de crawl, vous devez acquérir plus de backlinks à travers des campagnes de Netlinking. Mais, aussi vous pouvez aussi orienter votre crawl.
Dans la plupart des cas, il s'agit d'une meilleure option pour optimiser votre allocation de budget crawl.
Le budget crawl est-il un facteur de classement SEO ?
Non. Le budget crawl n'est pas un facteur de classement sur Google ; cependant, il peut indirectement avoir un impact positif sur les performances de recherche.
Voici ce que Google dit sur la question :

Pourquoi Google ne parcourt pas mon site ?
Googlebot ne crawl pas votre site Web seulement si : il n'est pas au courant de l'existence de vos sites ou si vous avez demandé à Googlebot de ne pas explorer votre site Web.
Si votre site Web est nouveau, Google doit être informé de son existence. Google trouvera votre site Web à partir d'autres sites liés au vôtre ou en vous demandant de l'indexer via Google Search Console. Googlebot est même capable de trouver des pages orphelines qui ne sont plus dans la structure du site pour une raison ou autre (refontes- ancien produits…).
Pour ce dernier, vous devez vérifier votre fichier robots.txt et vous assurer que vous n'empêchez pas Google de parcourir votre site Web. Pour cela, naviguez vers votre site web et ajoutez /robots.txt/ à l'URL.

Comment puis-je établir mon budget crawl ?
Comme je l'ai mentionné, vous pouvez fixer votre budget d'exploration à un niveau supérieur à ce que Google juge acceptable.
Mais si Googlebot nuit aux performances de vos serveurs, vous limitez le taux d'exploration maximal de Google via Google Search Console.
Dernière information de Google sortir le 1er décembre 2020
Rien de nouveau mais c'était nécessaire de les rappeler.
Google a publié un document d'aide intitulé “Guide du propriétaire d'un grand site pour gérer son budget de crawl“. Il s'agit d'un document pour aider les SEO et les développeurs à gérer les crawls de Googlebot sur leur site web.
Google définit d'abord qu'on doit penser à gérer son budget crawl :
- Les gros sites (plus d'un million de pages uniques) dont le contenu change souvent (une fois par semaine).
- Les sites de taille moyenne ou plus importante (plus de 10 000 pages uniques) dont le contenu change très rapidement au quotidien.
- Pour tous les autres, le budget d'exploration est surestimé.
Le document est divisé en ces sections :
- Théorie générale du crawling
- Bonnes pratiques
- Surveillez l'exploration et l'indexation de votre site
- Réduction de l'usage du crawl en cas d'urgence
- Mythes et faits sur le crawling
Quelques remarques :
- Le crawl est un facteur de classement : Faux : Améliorer votre taux de crawl n'entraînera pas nécessairement de meilleures positions dans les résultats de recherche. Google utilise de nombreux signaux pour classer les résultats, et bien que le crawling soit nécessaire pour qu'une page soit dans les résultats de recherche, ce n'est pas un signal de classement. Là c'est claire une fois pour toute.
- La directive “nofollow” a une incidence sur le budget crawl : En partie vrai : Toute URL qui est explorée affecte le budget de crawl, donc même si votre page marque une URL comme nofollow, elle peut toujours être explorée comme une autre page de votre site, ou n'importe quelle page sur le web, ne marque pas le lien comme nofollow.
- Plus votre contenu est proche de la page d'accueil, plus il est important pour Google : C'est en partie vrai : la page d'accueil de votre site est souvent la page la plus importante de votre site, et les pages liées directement à la page d'accueil peuvent donc être considérées comme plus importantes, et donc explorées plus souvent. Toutefois, cela ne signifie pas que ces pages seront mieux classées que d'autres pages de votre site. Il y a des limtes 🙂 .
- Les URLs alternatifs et le contenu intégré comptent dans le budget de crawl : C'est vrai : en général, toute URL explorée par Googlebot est prise en compte dans le budget de crawl d'un site. Les URLs alternatifs, comme AMP ou hreflang, ainsi que le contenu intégré, comme CSS et JavaScript, y compris les extractions XHR, peuvent devoir être explorés et consomment le budget crawl d'un site.
Qu'est-ce que la planification du crawl aka crawl scheduling ?
La planification du crawl dans le crawling web est le classement des documents (les documents peuvent être des URL de pages web, des images, des feuilles de style en cascade CSS, des fichiers javascript JS, des PDF ou d'autres documents), et l'attribution de la priorité et de la fréquence de visite par les crawlers web des moteurs de recherche. La planification du crawl est principalement basée sur l'importance et la fréquence de changement des documents.
Qu'est-ce que la planification et la demande de crawl ?

La deuxième partie du budget de crawl est la “programmation” ou la “demande de crawl”. Le web est immense et ne cesse de croître. Si l'on considère également le nombre de pages Web individuelles et même le contenu généré par les utilisateurs, comme les tweets (qui sont aussi des pages Web), indexés et explorables, la tâche devient gigantesque. Il est nécessaire pour les moteurs de recherche de construire des systèmes évolutifs et efficaces.
C'est pourquoi un calendrier d'exploration est élaboré au fil du temps en fonction de l'importance des pages Web et de la fréquence de leurs modifications. Si votre page Web ne change que rarement, elle risque d'être moins souvent explorée que les pages Web qui subissent des modifications substantielles (des éléments qui font une réelle différence pour les utilisateurs des moteurs de recherche, comme le prix sur un site e-commerce), fréquemment.
Si votre page Web n'est pas souvent explorée, cela ne signifie pas automatiquement qu'elle est de mauvaise qualité, mais il existe souvent une corrélation entre le nombre de pages de mauvaise qualité sur un site et le faible taux d'exploration. Ces pages ont tendance à être de faible importance et à être facilement accessibles (c'est-à-dire qu'elles sont nombreuses et qu'elles sont pour la plupart identiques, répondant aux mêmes groupes de requêtes les unes que les autres).
Au fil du temps, en surveillant l'évolution et l'importance de vos pages Web, les moteurs de recherche se font une idée de la fréquence à laquelle ces pages doivent être consultées. Lorsque ces deux facteurs (charge de host et demande de crawl) sont combinés, on obtient le concept que nous, les référenceurs, connaissons sous le nom de “budget de crawl”.
Qu'est-ce que le “Crawl Rate” ?
La crawl rate d'un site Web est la vitesse à laquelle un robot crawl votre site Web. Elle est basée sur le nombre de pages consultées par seconde par le robot d'exploration du moteur de recherche de Google lorsqu'il parcourt le site. La vitesse la plus rapide de traversée du site est de 10 fois par seconde. Toutefois, il est important de noter que tous les sites Web et la capacité de charge de leur hôte sont différents. Il n'existe donc pas nécessairement de vitesse d'exploration “standard” pour un type de site particulier. Chaque site et ses composants ainsi que son hébergement sont uniques.
Est ce que le Javascript ralentit le crawl ?
Javascript peut certainement rendre le crawl de vos pages web plus compliquée pour les moteurs de recherche, et encore plus lorsqu'il s'agit de lire le contenu des pages, ce qui pourrait avoir un impact négatif sur votre référencement.
Vous avez besoin d'aide pour votre SEO Technique Cliquez ici.