
Le Guide Complet du robots.txt
Le fichier robots.txt existe depuis 25 ans.
Les origines de robots.txt, remontent au milieu des années 1990, à l'époque où les « spiders » du web parcouraient Internet pour lire les sites web. Mais il faut attendre l’année 1994 quand Martijn Koster a créé un robot d'indexation qui a provoqué un mauvais cas de DDOS sur ses serveurs. En réponse à cela, il a inventé ce fichier et commencé à rédiger une proposition d’interprétation : Robots Exclusion Protocol (REP). L’idée, c’est de guider les crawlers et les empêcher d’atteindre certaines zones du site.
Qu'est-ce qu'un fichier robots.txt ?
Pour le dire simplement, c’est un petit fichier robots.txt qui informe les robots, dont Googlebot, des endroits où ils peuvent et ne peuvent pas aller sur un site web.
Cela peut être utile pour s'assurer que les zones privées ne sont pas indexées dans les résultats de recherche, mais cela peut également être utilisé pour optimiser le budget crawl de votre site web en s'assurant que Googlebot ne visite que les pages de votre site web que vous souhaitez réellement explorer régulièrement.
Comment configurer le fichier robots.txt ?
1. Le fichier robots.txt doit être à la racine de votre site web.
2. Un seul fichier robots.txt par site web.
3. Le nom du fichier (robots.txt) doit toujours être en minuscules.
4. Et mettre toujours le nom du fichier aux pluriels : « robots ».
Un exemple de structure de fichier robots.txt :
User-agent: *
Disallow: /video-seo/
Disallow: /gmb/
Disallow: /local-seo/prix.html
En fait ici :
- User-agent: * veut dire que l’accès à tous les bots.
- Le bot n’ira pas explorer les répertoires /video-seo/ ainsi /gmb/ du serveur ni le fichier /local-seo/prix.html.
- Le répertoire /gmb/, par exemple, c’est la page https://www.mlocalseo.com/ gmb/.
- C’est une ligne par répertoire à exclure de l’aspiration du bot avec la commande : Disallow
User-agents
Chaque moteur de recherche s'identifie avec un user-agent différent. Vous pouvez définir des instructions personnalisées pour chacun d'entre eux dans votre fichier robots.txt. Il existe des centaines d'user-agents, mais voici quelques-uns qui sont utiles pour le référencement :
Google : Googlebot
Bing : Bingbot
Vous pouvez également utiliser le jocker (*) pour attribuer des directives à tous les user-agents.
Par exemple, disons que vous voulez empêcher tous les robots, sauf Googlebot, d'explorer votre site. Voici comment vous feriez :
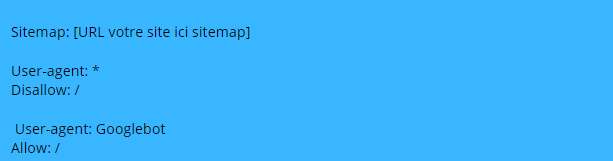
Directives
Les directives sont des règles que vous voulez que les user-agents déclarent suivent.
Disallow
Utilisez cette directive pour demander aux moteurs de recherche de ne pas accéder aux fichiers et aux pages qui se trouvent sous un chemin spécifique. Par exemple, si vous voulez empêcher tous les moteurs de recherche d'accéder à votre blog et à tous ses articles, votre fichier robots.txt pourrait ressembler à ceci :

Sitemap
Utilisez cette directive pour préciser aux moteurs de recherche l'emplacement de votre sitemap.

En générale, je mets toujours mon sitemap dans mon fichiers robots.txt mais vous pouvez le faire dans le GSC.
Voici un exemple de fichier robots.txt utilisant la directive sitemap :

Le fichier robots.txt est présent sur tous les sites web.
Où se trouve le fichier robots.txt sur un site ?
Si vous avez déjà un fichier robots.txt sur votre site web, il sera accessible à l'adresse tonsite.com/robots.txt. puis accédez à l'URL dans votre navigateur.
Pourquoi avez-vous besoin de robots.txt ?
Les fichiers robots.txt contrôlent l'accès des robots d'indexation à certaines zones de votre site. Bien que cela puisse être très dangereux si vous interdisez accidentellement à Googlebot d'explorer l'ensemble de votre site, il existe certaines situations dans lesquelles un fichier robots.txt peut être vraiment très utile voilà quelques exemples qui me viennent dans la tête. Mais je suis certains étant consultant seo aka Freelance SEO vous en avez pleins.
Voici quelques cas d'utilisation courants :
Empêcher le contenu en double d'apparaître dans les SERPs
Garder des sections entières d'un site web privées
Préciser l'emplacement des plans du site
Empêcher les moteurs de recherche d'indexer certains fichiers sur votre site web (images, PDF, etc.)
Spécifier un crawl delay afin d'éviter que vos serveurs ne soient surchargés lorsque Googlebot crawl plusieurs éléments de contenu à la fois.
Comment créer un fichier robots.txt
Si vous n'avez pas encore de fichier robots.txt, il est facile d'en créer un. Il suffit d'ouvrir votre note pad .txt et de commencer à taper des directives. Par exemple, si vous souhaitez interdire à tous les moteurs de recherche d'explorer votre répertoire /admin/, voici à quoi cela ressemblerait :

Mais aussi il y a d’autres méthode pour créer un fichier robots.txt par exemple si vous avez un site wordpress le plugin yoast le fait aisément.
L'avantage d'utiliser un tel outil est qu'il minimise les erreurs de syntaxe. C'est une bonne chose, car une seule erreur peut entraîner une catastrophe en matière de référencement naturel pour votre site.
Aussi, Google à un superbe article sur le processus de création du fichier robots.txt, et vérifier si votre fichier est correctement configuré.
Bonnes Pratiques robots.txt
Utilisez une nouvelle ligne pour chaque directive.
Chaque directive devrait se situer sur une nouvelle ligne. Sinon, les moteurs de recherche seront confus.
C'est mauvais :

C'est Bon

Simplifier les instructions
Non seulement, vous pouvez utiliser le jocker (*) pour appliquer les directives à tous les user-agents, mais aussi pour faire correspondre les modèles d'URL lors de la déclaration des directives. Par exemple, si vous voulez empêcher les moteurs de recherche d'accéder aux URL des catégories de produits paramétrées sur votre site, vous pouvez les lister comme ceci :

Utilisez la lettre “$” pour spécifier la fin d'une URL
Inclure le symbole “$” pour marquer la fin d'une URL. Par exemple, si vous voulez empêcher les moteurs de recherche d'accéder à tous les fichiers.pdf de votre site, votre fichier robots.txt pourrait ressembler à ceci :

Dans cet exemple, les moteurs de recherche ne peuvent pas accéder aux URL se terminant par .pdf. Cela signifie qu'ils ne peuvent pas accéder à/fichier.pdf, mais ils peuvent accéder à /fichier.pdf?id=5290 parce que cela ne se termine pas par “.pdf”.
N'utilisez qu’un user-agent par site.
Si vous spécifiez le même user-agent plusieurs fois, cela ne dérange pas Google. Il se contentera de combiner toutes les règles des différentes déclarations en une seule et de les suivre. Par exemple, si vous aviez les user-agents et directives suivants dans votre fichier robots.txt…
Utiliser un fichier robots.txt distinct pour chaque sous-domaine
Robots.txt ne contrôle que le comportement du crawler sur le sous-domaine où il est hébergé. Si vous souhaitez contrôler l'exploration d'un sous-domaine différent, vous aurez besoin d'un fichier robots.txt séparé.
Par exemple, si votre site principal se trouve sur tonsite.com et votre blog sur blog. tonsite.com, vous aurez besoin de deux fichiers robots.txt. L'un doit aller dans le répertoire racine du domaine principal, et l'autre dans le répertoire racine du blog.
Comment faire un audit de votre fichier robots.txt ?
L’idée, c’est de vérifier si votre fichier ne contient pas d’erreurs.
Les erreurs de robots.txt peuvent se glisser assez facilement sur le net, il est donc utile de garder un œil sur les problèmes.
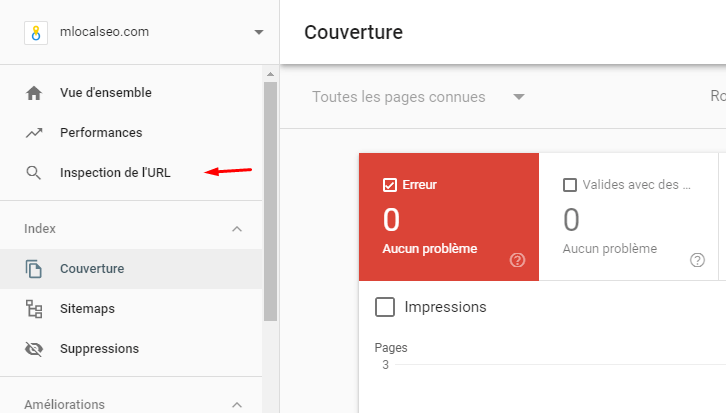
Pour ce faire, vérifiez régulièrement les problèmes liés à robots.txt dans le rapport “Couverture” de la console de recherche. Vous trouverez ci-dessous quelques-unes des erreurs que vous pourriez voir, leur signification et la manière dont vous pourriez les corriger.
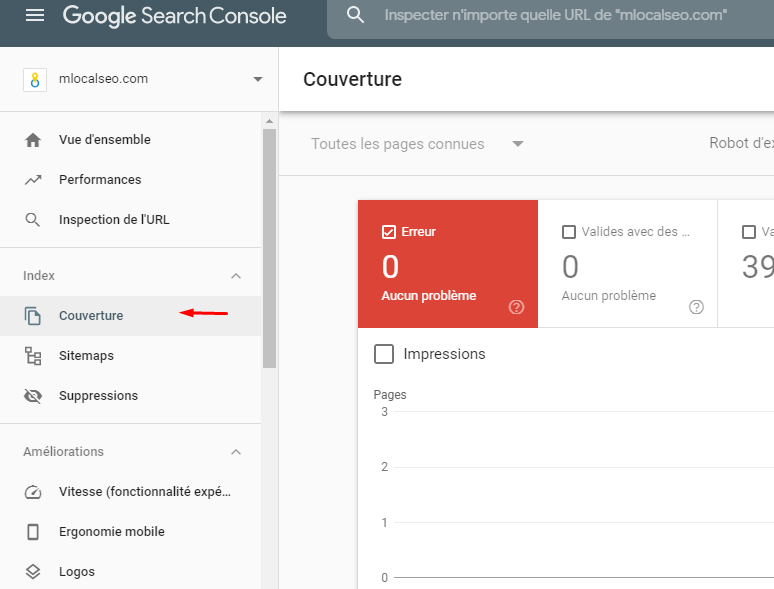
Collez une URL dans l'outil d'inspection des URL de Google dans le GSC. Si elle est bloquée par le fichier robots.txt, vous devriez voir quelque chose comme ceci :

Foire aux Questions
Voici quelques questions fréquemment posées qui n'ont pas trouvé leur place ailleurs dans notre guide, car les choses évolue rapidement dans le petit monde du seo en ce moment. Mais, en fait c'est toujours comme ça…
Quelle est la différence entre ces trois types d'instructions pour les robots ?
Tout d'abord, robots.txt est un véritable fichier texte, alors que les meta-bots et les x-bots sont des meta-directives. Au-delà de ce qu'ils sont réellement, les trois remplissent des fonctions différentes. Robots.txt dicte le comportement d'exploration du site ou du répertoire, tandis que les meta-bots et les robots-x peuvent dicter le comportement d'indexation au niveau de la page individuelle (ou de l'élément de page).
Que se passe-t-il si, j'interdis l'accès à un contenu non indexé dans robots.txt ?
Google ne verra jamais la directive “noindex” car il ne peut pas explorer la page.
Quelle est la taille maximale d'un fichier robots.txt ?
500 kilo-octets
Où se trouve le fichier robots.txt dans WordPress ?
Au même endroit : danstonnomdomaine.com/robots.txt.
Comment modifier le fichier robots.txt dans WordPress ?
Soit manuellement, soit en utilisant un des nombreux plugins de WordPress comme Yoast qui vous permet de modifier le fichier robots.txt depuis le back-office de WordPress.
Est ce que Google supporte Robots.txt Noindex ?
Google a officiellement annoncé que GoogleBot n'obéira plus à une directive de Robots.txt relative à l'indexation. Les éditeurs qui s'appuient sur la directive robots.txt relative à l'indexation ont jusqu'au 1er septembre 2019 pour la supprimer et commencer à utiliser une alternative.
Vous avez besoin d’être pour booster votre trafic SEO.
